Giải Nevalina 2010
Giải Nevalina năm nay được trao cho bạn Spielman (đại học Yale). Bài dưới đây nói qua về công trình của Spielman. Sáng nay vừa mở máy tính ra thì bạn Tào đã làm ngay hai bài dài ngoằng nói về tất cả các giải thửơng của IMU, bạn nào quan tâm rất nên đọc. Bác Sơn Đàm cũng viết một bài rất hay về các công trình được giải liên quan đến vât lý.
Tôi viêt thêm về chủ đề của Spielman vì chủ đề này có những bài toán mở (open problem) tương đối dễ hiếu và thú vị. Bạn có thể (và nên) đọc song song với bài của Tào, và tham khảo thêm bài của Spielman và Teng trên proceeding của IMU 2002, bài này cũng rất dễ đọc và không cần nhiều kiến thức chuẩn bị.
Công trình tôi muốn nói tới là “Smoothed Analysis” của Spielman và Teng. Hai bạn này chú trọng đến simplex algorithm, nhưng tốt hơn là ta phát biểu khái niệm này một cách tổng quát.
Mục đich của bạn Spielman và Teng là phân tích hiện tượng sau:
Có một dữ liệu (data) 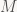

Câu hỏi cơ bản nhất trong lý thuyết tính toán: Máy chạy mất bao lâu ?
Để trả lời câu hỏi này, người ta thường phân tích trường hợp “xấu nhất” (worst case analysis-worst matrix
Nhưng, trong thực tế, simplex algorithm rất hỗn. Nó cười khảy vào các kết quả trên và luôn chạy băng báng. Điều này làm các nhà toán học rất tức tối, phải làm cho ra ngô ra khoai. Muốn vậy, phải dùng một ít xác suất.
Sau một số lớn các cách giải thích chưa được hoàn toàn trọn vẹn, cách đây chừng 10 năm, Spielman và Teng đưa ra cách giải thích sau: Trong tính toán luôn luôn có tiếng ồn, sai số (noise). Khi bạn đo một dữ liệu, mặc dầu kết quả thực là 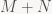
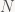
Định lý chính của Spielman và Teng nói là nếu 
Ma trận Gauss là ma trận ngẫu nhiên với các phần tử là biến Gauss độc lập. Xác suât cao là xác suất tiến tới 1 nếu 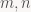
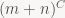

Cách giải thích của S-T rất hợp lý, vì nó cho phép
đến từ worst case analysis. Tôi thấy nó thú vị vì thường trong các ứng dụng dùng đén thuật toán, tiếng ồn và sai số luôn là thủ phạm của các vụ rắc rối khi ta cần tính một cái gì cụ thể, nhưng ở đây nó lại có vai trò “tích cực”. Sai số làm cho các ma trận xấu tính không thể trở nên quá xấu.
Đây là ý tưởng chính trong công trình dẫn tới giải Nevalina của Spielman và giải Godel và Fulkerson chung cho hai người.
Định lý S-T được phát biểu dưới dạng phép toán (algorithmic), vậy mấu chốt toán học của nó ở đâu ? Quan sát quan trọng nhất của S-T có lẽ là bổ đề sau.
Để phát biểu bổ đề này, ta cần một vài khái niệm. Trước hết, để đơn giản hóa vấn đề, ta giả sử cả 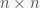

ký hiệu là 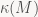
Một ma trận trong trường hợp xấu nhất có thể có condition number rất lớn (thậm chí là vô cùng nếu bậc của ma trận nhỏ hơn 
hay nhiều chiều, không xơi được).
Bổ đề (S-T). Nếu 


Nội dung của bổ đề này là dù 

Chứng minh bổ đề trên không khó. Nhưng phần phân tich thuật toán khá phức tạp; một cách chứng minh đơn giản hơn được đưa ra sau đó bởi Vershynin.
Bây giờ nói tới bài toán mở. Ý tưởng của S-T rất hay. Nhưng giả thuyêt N là ma trận Gauss hơi mạnh. Trong các dữ liệu cụ thể, thường các số liệu là sổ nguyên, hoặc được viêt dưới dạng thập phân với một vài chữ số sau dấu phẩy. Bản thân máy tính cũng chỉ làm việc được với các số biểu diến được một cách hữu hạn mà thôi. Các số được sampled từ phân bố Gauss thì luôn là vô tỷ, thậm chí không phải số đại số. Vậy giả thuyết gần với thực tế hơn là các phần tứ của
Trường hợp đơn giản (vầ đặc trưng) nhất là khi 


Bước đầu tiên là chứng minh bổ đề S-T cho ma trận Bernoulli. Vấn đề này rất gần với Universality (hay Invariance) principle trong toán vật lý (xem bài của Tào về Smirnov). Nôm na mà nói, thường ta tin rằng một định lý đúng với một mô hình (hay phân bố) ngẫu nhiên nào đó thì cũng đúng với các mô hình khác. Nhưng chứng minh điều này nói chung là khó, vì thường các cách chứng minh hay dùng các tính chất cụ thể của phân bố đã cho, chẳng hạn cách ST chứng minh bổ đề dùng tính chất là phân bố Gauss trong không gian nhiều chiều có tính đối xứng rất cao (rotational invariant). Tính chất này không đúng trong trường hợp Bernoulli. Một bài toán con của bổ đề S-T trong trường hợp Bernoulli là bài toán khá nổi tiếng sau:
(Định lý Komlos, 1966): Với 
Định lý này nói rằng một ma trận ngẫu nhiên 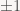
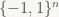
Trong trường hợp ta lấy
Bạn có thể xem các mở rộng của bổ đề S-T tại đây. Công cụ chủ yểu để mở rộng bổ đề này đến từ Additive Combinatorics. Hiện vẫn còn một số vấn đề mở rất thú vị với bổ đề này. Về Định Lý S-T,chỗ vướng mắc, như tôi còn nhớ, là trong phần phân tích thuật toán, có dùng những tính chất khác khá mạnh của phân bố Gauss trong môt số Lemma mang tính kỹ thuật.

\kappa(M) la ty so giua eigenvalue lon nhat va nho nhat.
The neu M khong vuong thi dinh nghia cai \kappa(M) the nao ha ba’c?
\kappa la ty so giua singular values chu khong phai eigenvalues, hai khai niem nay nghe hao hao nhung rat khac nhau.
Thuong trong cac sach giao khoa toi chi thay ho dinh nghia cho ma tran vuong. Chac cac ma tran khong full rank neu co gang ta
cung co the dinh nghia duoc, chang han restrict the operator to a subspace, nhung toi khong biet citation cu the.
Chac sach cua Trefethen va Golub and van Loan discuss chu de nay rat ky.
http://en.wikipedia.org/wiki/Condition_number
Anh Van co the giai thich tai sao ma tran N lai co dang Gauss ma khong phai la dang khac duoc k? Cai nay lam sao ma biet duoc?
Cho mot input M ta co mot nhieu ngau nhien N the thi cai N nay lam sao ma biet no tuan theo luat phan phoi nao? neu biet cach do duoc phan phoi cua N thi co the phan loai cho lop input cua M ma co cung nhieu N?
Câu hỏi rất hay. Phân bố Gauss chỉ là giả thiết thông dụng khi người ta muốn model tiếng ồn, sai số. Giả thiết này có thể đúng có thể sai. Chang han trong mot so data, giả thiết sai số có phân bố Gauss có vẻ hơi mạnh.
Trong trường hợp về định lý ST, trong đoạn cuối của blog, tôi có đề cập đến các phân bố khác.
Nói sang một bài toán khác (không liên quan đến ĐL ST, nhưng liên quan đến câu hỏi của bạn): trong statistics, machine learning, data mining etc, một vấn đề thông dụng là phân loại dữ liệu. Đại loại là bạn có một đống data, và muốn biết: data có phân bố Gauss hay không ? Nếu là phân bố Gauss, các tham số (mean, variance vv) cua no la gi ? vv Cai nay co ca mot ly thuyet rat do so va hay, vi no lien quan nhieu den high dimensional geometry, theoretical computer science va nhieu linh vuc khac.
Bạn có thể đọc qua quyển Aspects of Multivariate Statistical Theory của Muirhead neu quan tam.
Bài viết của anh rất thú vị, ngôn từ dí dỏm, rất dễ hiểu về ý tưởng của vấn đề. Tuy nhiên với người ko chuyen về thuật toán như em thì cũng rất trừu tượng :). Cho em hỏi một chút (có thể là hơi stupid 😀 ):
1. “Anh Van co the giai thich tai sao ma tran N lai co dang Gauss ma khong phai la dang khac duoc k? Cai nay lam sao ma biet duoc?” — cái này có liên quan đến Định lý giới hạn trung tâm không anh?
2. Giả sử cho bài toán QHTT cụ thể:
Tìm Max: x + y + z
Với các ràng buộc: x + y =0; x – y = 0;
Thì M là ma trận (1, 1; 1, -1) (cỡ 2×2)
Thế N ở đây sẽ là gì hoặc được hiểu như thế nào ạ? (Chẳng lẽ cứ lấy N cỡ 2×2 là ma trận Gauss tùy ý hoặc “các phần tứ của N có phân bố rồi rac trên một số hữu hạn điểm” tùy ý)
@ Tuan
(1) Em xem cau tra loi o tren (@ Son).
(2) Trong thuc tu, thi variance cua ma tran N thuong phu thuoc vao
so lieu. Gia su so lieu nho thi sai so nho, so lieu lon thi sai so lon.
(3) Chu y day la bai toan thuoc loai dat mo hinh de giai quyet mot hien tuong thuc te (gan nhu cac bai toan trong vat ly ly thuyet). Khi chua co mot cach giai thich thoa dang nao, thi ta thuong chon mo hinh de nhat (cu the truong hop nay la Gaussian). Sau do co the giai thich cho mot mo hinh roi, thi ta co the xet toi cac mo hinh thuc te hon.
Trong thuc te, chang nhung bien Gauss chua that thich hop, ma
con nhieu technicality khac, chang han
mot so entry cua matrix bang 0 thi khong co sai so gi ca. Boi vay mo hinh cho that chinh xac cung chua co, va bai toan se kho hon cai ma Spielman va Teng lam.
(1) Giải Nevalina năm nay được trao cho bạn Spielman, Công trình tôi muốn nói tới là “Smoothed Analysis” của Spielman và Teng. — chắc là Teng đã hơn 40 tuổi hả anh?
(2) Công trình này đã có được cách đây khoảng 10 năm, nhưng nay mới đươc trao giải Nevalina, vậy chắc các công trình trao vào các năm 2002, 2006 được đánh giá tốt hơn phải ko anh?
(3) Trong tính toán luôn luôn có tiếng ồn, sai số (noise). Khi bạn đo một dữ liệu, mặc dầu kết quả thực là M, nhưng trên thực tế không bao giờ ta nhận được M. — về mặt ý tưởng chung thì em vẫn thấy câu này khó hiểu, về trực giác, máy tính làm việc với các con số cụ thể, vậy mà khi tính toán lại sinh ra sai số !!!
Anh Van oi, gia su $\mu$ la phan phoi Gaussian. Choose $n$ random points (x_1,…,x_n) in $R^d$ independently according to $\mu$, co nghia la $x_i$ la Gaussian random variables co phai khong aj?
@Blue: Yes
@Le Van Tuan: Cai nay toi khong ro lam. Giai thuong nay cung la tong cua nhieu cong trinh, Smoothed analysis la cong trinh trong tam nhat. Cac giai thuong cac nam truoc cung vay, nen rat kho so sanh.