Phần nhiều thủ đo các nước được lựa chọn là vì nó có vị trí nổi bật trong đời sống văn hoá chính trị, vị trí giao thông thuận lợi (thường cạnh sông lớn hay biển), và các triều đại nối tiếp nhau ít khi thay đổi một thủ đô được chọn ra bởi các tiêu chí đó. Ví dụ, Hà nội từ khi Lý Công Uẩn dời đô, luôn là thủ đô chỉ trừ độ 100 năm nhà Nguyễn. Paris, Hà nội của châu Âu, cũng có hoàn cảnh hao hao như thế.
Ở Trung quốc, nhà Tần được Tần Thuỷ Hoàng lập ra, tuy tồn tại ngắn ngủi, nhưng đã tạo nên được cái chuẩn cho môt nhà nước tập quyền: đường xá, tiền tệ, chữ viết, phương tiện đo lường được chuẩn hoá. Nhà Hán kế tục nhà Tần, là triều đại phong kiến rực rỡ nhất của Trung Quốc (người TQ sau cũng tự gọi mình là người Hán).
Nhà Tần đóng đô ở Hàm Dương, trong lãnh thổ của họ, ở phía Tây của Trung quốc lúc đó. Nhà Hán cũng đóng đô trong vùng đó, gọi là Tràng An (hay có lúc là Tây An hay Tây Kinh). Hiện khu vực này có quận Vị Ương có lẽ là địa điểm cung Vị Ương của nhà Hán ngày xưa, sân bay Hàm Dương ở cách đó không xa, và lăng mộ của Tần Thủy Hoàng và đội quân đất nung của ông ta.
Nhà Hán kéo dài 400 năm, nứa sau của nó, gọi là Đông Hán, thủ đô chuyển sang Lạc Dương, phía đông Tràng An (đất nước Hàn thời Chiến quốc), nhưng cũng cách đó không xa. Hai địa điểm này luôn được coi là kinh đô của Trung quốc trong chừng một nghìn năm liền.
Nhà Hán đổ, các lực lương phong kiến đánh nhau lung tung, từ các sứ quân đến thời Tam quốc, qua nhà Tấn cũng chỉ được vài chục năm yên ổn lại đánh nhau tiếp, tiếp theo là thời Ngũ Hồ, dân chúng điêu đứng. Đến nhà Đường mới bắt đầu tạm ổn. Đây là thời kỳ rực rỡ thứ hai của phong kiến Trung quốc.
Nhà Đường (thế kỷ 7-10) kế tục nhà Hán, tiếp tục đóng đô ở Trường An. Lúc cực thịnh thành phố có tới 1 triệu dân, là môt trung tâm thương mại văn hóa lớn nhất thế giới lúc đó (để tạm so sánh, Paris trong thế kỷ 14 là thành phố lớn nhất châu Âu có chừng 200 nghìn dân).
Nhà Đường đứng được gần 300 năm, cho đến lúc nạn cát cứ của các tiết độ sứ làm nó kiệt quệ, và Trung quốc, như thường lệ, lại đi tiếp vào môt giai đoạn chia năm sẻ bảy (Ngũ đại thâp quốc). Giai đoạn này hỗn độn không thể nào tóm tắt được, nhưng đối với người Việt thì nó lại rất quan trọng, vì đây là lúc Viêt Nam bắt đầu giành được độc lâp và tách ra khỏi Trung quốc. Ngô quyền đánh bại quân Nam Hán trên sông Bạch Đằng. Nam Hán khi đó là môt trong mười nước (thập quốc), lãnh thổ ở Quảng đông-Quảng tây hiện nay.
Nhà Tống thống nhất Trung Quốc, chọn nơi mới mà đóng đô là Biện Kinh (Khai Phong), về phía đông hai kinh đô cũ. Tống thái tổ muốn tránh vết xe đổ của nhà Đường, tước quyền lực của các tướng lĩnh, trong dụng văn thần. Kết quả là kinh tế, văn học thời Tống phát triển khá mạnh, nhưng đánh nhau thì đánh đâu thua đấy. Đặc biêt thất thế hoàn toàn trước các thế lực phương Bắc. Được hơn 100 năm, nước Kim chiếm mìền Bắc Trung quốc, kể cả kinh đô Biện Kinh (đất cũ của Tần Thuỷ Hoàn hoàn toàn nằm trong phạm vi này). Triều đình Tống sơ tán xuống miền Nam, lâp ra Nam tống, đóng đô ở Hàng Châu.
Mặc dầu là chính phủ sơ tán, và lần đầu tiên triều đình Trung quốc mất sự cai quản vùng lưu vực sông Hoàng Hà, cái nôi của Trung quốc cổ đại, Nam Tống có những thành công nhất định như môt quốc gia lớn. Kinh đô mới Hàng Châu đã là môt đô thị phồn vinh và vẻ đẹp của nó được các văn nhân ca tụng khá nhiều.
Gần 1500 năm đã qua từ Hàm Dương của Tần Thuỷ Hoàng đến Hàng Châu của Nam Tống. Và có lẽ bạn đã nhận ra, không thấy Bắc Kinh đâu cả. Bởi thật sự, nó chẳng ở đâu. Thời Chiến quốc, Bắc Kinh là một thị trấn thuộc nước Yên, môt nước lếp vế nhất trong 7 nước Chiến quốc, mà nhiệm vụ chính là ngăn chặn các bộ tộc phương Bắc tràn xuống. Ai đến Bắc Kinh ngày nay, đều đi chơi Vạn Lý Trường Thành, trong phạm vi thành phố luôn, tất phải đặt câu hỏi tại sao thành phòng thủ người Hung nô, tất phải ở biên giới cực bắc, lại xây ngay thủ đô ? Vạn Lý trường thành, được xây từ đời Chiến Quốc, kế qua Tần Hán đều tiếp tục xây dựng, khi đó Bắc Kinh vẫn là môt thị trấn biên giới, không bao giờ có vai trò gì quá quan trọng.
Người biến Bắc Kinh thành thủ đô Trung quốc lần đầu tiên, lại là những người mà người Hán coi là man di. Người Kim sau khi đánh bại Bắc tống, bỏ Biẹn Kinh, đã lập môt thành đô tạm thời tại vùng đất Bắc Kinh hiện nay. Chính quyền Kim vẫn tương đối ở trong tình trạng bộ lạc, vai trò thủ đô chưa quá nổi bật. Bắc Kinh, với vai trò là trung tâm chính trị cả Trung quốc, được bắt đầu từ nhà Nguyên của người Mông Cổ, cũng lại là một dân tộc phương Bắc khác tràn xuống. Hốt Tất lIệt cho xây dựng Đại đô ỏ Bắc Kinh, biến đô thị này thành môt thành phố lớn và phồn thịnh. Lý do người Kim cũng như người Mông cổ chọn địa điểm này chắc phần lớn vì vị trí cực bắc của nó, tức là gần căn cứ địa của họ nhất.
Qui mô của đế quốc Mông cổ biến Đại Đô thành môt thành phố quốc tế, thông thương với nhiều quốc gia trên thế giới. Dân cư trong thành rất đa dạng, có vô số sắc tộc. Bạn có thể độc qua tác phẩm Ỷ thiên đồ long ký (Cô gái Đồ long) của Kim Dung để thấy không khí Đại Đô trong thời gian này. Nhất là (các) người yêu của nhân vật chính Trương Vô Kỵ, thì mang tính đại diện rất cao, mỗi cô một quốc tịch. Ắt hẳn đó phải là ước mơ của nhà văn, thể hiện thật sinh động qua trang giấy. Nhưng cuối cùng thì Kim Dung vẫn phải để Vô Kỵ, dù thân mang tuyệt kỹ, cũng vẫn sợ vợ như thường. Bệnh sợ vợ này, nghìn năm trôi qua hình như chỉ có nặng lên, ngay gần đây đại biểu quốc hội cũng đã phải bàn đến, vì nó còn ảnh hưởng tới giao thông.
Nhà Nguyên tồn tại được gần 100 năm, khi đế quốc suy tàn, người Hán nổi lên giành lại đất nước. Thú vị ở chỗ là trước hết họ đánh lẫn nhau khá hăng, rồi khi Chu Nguyên Chương toàn thắng, đánh bại hết các thủ lĩnh Trung Quốc khác, mới đem quân tiến về giải phóng thủ đô để đuổi người Mông Cổ đi. Chế độ Mông Cổ đã mọt ruỗng, và cũng có phần họ vẫn coi mảnh đất cơ bản của họ là Koracorum, nên Đại Đô được giải phóng không mấy khó khăn. Các trận chiến thật sự giữa nhà Minh và Bắc Nguyên chủ yếu diễn ra trên đất Mông Cổ, giữa các nhân vật phụ của Ỷ Thiên đồ long ký là Vương Bảo Bảo (anh vợ của Trương Vô Kỵ) và Từ Đạt. Các nhân vật chính, như ta đã biết, đang bận một cuộc chiến đấu khác cam go hơn rất nhiều.
Chu Nguyên Chương là người Giang Tô, lập tức đóng đô tại Nam Kinh, và xem ra Bắc Kinh lại sẽ rơi vào quên lãng. Các cách nó trở lại làm thủ đô, cũng khá thú vị.
Sau khi Minh Thái Tổ (Chu Nguyên Chương) chết, các vương thân tranh nhau làm vua. Người thắng là Chu Đệ (em của Chu Nguyên Chương), ông này trước khi làm vua, được phong là Yên vương, đất phong ở nước Yên thời Chiến Quốc. Chu Đệ lại chọn Bắc Kinh làm kinh đô, mặc về vị trí cũng như phong cảnh, văn hoá, có lẽ không bằng Hàng Châu, nhưng Bắc Kinh nằm trong căn cứ địa của ông ta. Tử cấm thành bắt đâu được xây dựng, và Bắc Kinh trở thành thủ đô ổn định của Trung quốc bắt đầu từ thời điểm này. Khi người Mãn Châu chiếm Trung Quốc, lâp ra nhà Thanh, sự lựa chọn cũng khá rõ ràng. Môt phần Bắc Kinh đã qua 300 năm liền là thủ đô, phát triển mạnh mẽ. Một phần nữa nó cũng gần mảnh dất căn bản của họ.
Ngày hôm nay, thì có thể đoán rằng vị trí thủ đô của Bác Kinh chắc sẽ duy trì mãi mãi. Còn cuộc chiến đấu của Trương Vô Kỵ và các đồng đội của anh, thì xem ra ngày càng vô vọng.
Còn 10 ngày nữa là bóng lăn, mà tình hình vẫn có vẻ lắng.
Hồi ngày xưa, vào giờ này, đã sôi lắm. Thể thao văn hoá, hay bản tin bóng đá (tiền thân của nó) ra hàng ngày, ra số nào hết số đấy từ sáng sớm. Ảnh thì mờ mịt vì được in trên loaj giấy rẻ nhất, nhưng chị em cũng cố căng mắt để xem thủ môn Daxaép đẹp giai. Thật ra thì với chất lượng giấy đó, in ảnh Breznhev vào cũng đẹp chả kém. Tức là nó rất bình đẳng về mặt nhan sắc.
Nói ngày xưa, là tự tố giác mình là già. Nhưng biết làm sao được, chuyện đang nói ở đây, là World Cup 1982, của 40 năm trước. 40 năm nghe thật kinh hoàng. Đó là khoảng thời gian dài bằng từ cách mạng tháng 8 (1945) cho tới thời kỳ đổi mới (1986). Dĩ nhiên, nếu bạn là đầu 8 đuôi to to, thì 45 hay 82 đều là ngày xưa, thuộc về các cụ khốt. Đó là trong trường hợp nếu bạn biết cụ khốt là ai.
Tại sao lại là 1982 mà không phải một năm nào khác? Lý do duy nhât ở đây, đó là World Cup đầu tiên mà trẻ con HN được xem một cách rộng rãi. TV vẫn là mặt hàng xa xỉ, nhưng lác đác phố nào cũng có, vài nhà một cái. Điện thỉnh thoảng tuần cũng được vài đêm. Muốn xem đá bóng, phải đoán trước phố nào sẽ có địen tối hôm đó, sau đó đến nhà một người quen có TV, nằm phục sẵn từ chiều để được chỗ tốt. Đi thế nó mới sướng, chứ còn như giờ tiện tay bấm cái remote một cái, rất không có đẳng cấp của một fan nghiêm túc.
Còn bản thân chương trình truyên hình đá bóng, cái mà chúng ta phải mua bản quyền hiện nay, năm nào cũng ầm ĩ, thì đã có Liên xô lo.
Nếu bạn hỏi đội tuyển mà người Việt yêu mến nhất của Espana 82 là đội nào, câu trả lời sẽ là Liên xô. Liên xô ở đây khác với nước Nga bây giờ rất xa. Đó là người bạn lớn (và duy nhất) của Việt nam khi đó. Bóng đá quôc tế ở VN, nếu được xem, là qua các chương trình TV của Liên xô. Giải bóng đá xô viết là giải quốc tế duy nhất mà người Việt có thể theo dõi, với El Classico là Dinamo Kiev đấu với Spartark Moskow. Đơn giản là chả có tiền để mua các chương trình khác; vả lại đang cấm vận, có mua chưa chắc đã có ai bán. Còn nếu bạn muốn hỏi cấm vận là gì, và cảm giác nó như thế nào, thì đó là cả một câu chuyện khác rất dài.
Xem mãi thì nó phải hay. Cũng như nếu cả lớp chỉ có một cô gái, thì, không nghi ngời gì, sớm muộn bạn sẽ phải thấy nàng là người xinh nhất. Công bằng mà nói, ở giai đoạn đó Liên xô đá cũng không dở. Các câu lạc bộ hàng đầu của họ như Dinamo Kiev, Dinamo Tbilitsi hay Spartark đều có bản sắc riêng, ra ngoài các câu lạc bộ phương Tây cũng phải nể mặt. (Kiev về sau có thời đá như lên đồng, nhưng đó là chuyện của vài năm nữa.)
Đội tuyển đúng bản sắc của Liên bang xô viết, có cầu thủ từ khá nhiều nước công hoà khác nhau, người Nga chắc chiếm chỉ độ nửa. Nổi nhất với chị em có lẽ là chàng Dasaev đẹp giai nói trên, là thủ môn của Spartark. Còn các cầu thủ khác cũng đá rât hay, mọi nhẽ. Oleg Blokhin, người Ukraina, là tiền đạo mũi nhọn, đã từng được quả bóng vàng. Đội trưởng Chivadze lại là người Gruzia. Nói chung là trong con mắt của bọn nhóc Hanội khi đó, thì Liên xô của chúng ta không thể thua được.
Mà có vẻ như thế thật. Trận đầu Liên xô đá với Brazil. Về sau đọc thì mới biết đội Brazil lúc đó được đánh giá là ứng viên số 1, và là một trong những đội Brazil mạnh nhất trong lịch sử (Socrates, Zico, Falcao). Nhưng lúc đó chả biêt các ông này mấy, Blokhin mới là nhất. Hiệp 1 Liên xô dẫn luôn 1-0. Cả nước, ít nhất là những chỗ có điện, sướng như điên. Phút 75 Brazil gỡ được một quả. Các cụ già, lập trường chính trị rât vững chắc, lẩm bẩm chắc là anh cả thả cho thế giới thứ 3 một quả. Thê quái nào còn vài phút nữa hết giờ thế giới thứ 3 lại làm thêm quả nữa, các cụ ngồi thừ hết cả ra.
Trận hai gặp đội lót đường New Zealand, đàn anh của chúng ta giã luôn 3 trái. Trận này không truyền, hoặc là mất điện không được xem. Hoặc có khi Liên xô cũng chả mua bản quyền truyên hình.
Trận ba với Scotland mới thực sự găng, vì hai đội cùng được 2 điểm. Vả lại, đấu với đội tư bản, nó sẽ khác. Scotland là đội mạnh hồi đó, khá nhiều sao như kiểu Archibal hay Strachan, chứ không chuối như bây giờ. Đã thế, họ lại còn dẫn trước. Các cụ bắt đầu lo, thành trì có vẻ mong manh quá, biết đâu. May thay hiệp hai thành trì làm luôn hai quả. Rồi đến cuối giờ còn 2 phút Scotland lại gỡ hoà. Trẻ con ngây hết cả ra chưa hiểu thế nào, sau được các cụ giải thích là quân ta vẫn được đi tiếp vì hơn tỷ số bàn thắng bàn thua (Scotland thua đậm Brazil). Ơ mừng ơi là mừng.
Nếu nhớ lại các trận đấu này, thì Liên xô đá có đường nét riêng của họ, chứ không nhạt nhoà như đội Nga về sau. Các cầu thủ kỹ thuật và thê lực đều tốt, không thua kém gì các cầu thủ chuyên nghiệp củaa phương Tây. Duy có họ chơi hơi chân phương, ít tiểu xảo, và đến cuối trận hay mất tập trung (cả hai bàn của Brazil và Scotland đều ở cuối trận). Giá có cao thủ từ Ý sang mách bảo là 5 phút cuổi, nếu tỷ số đang thuận lợi, thì đá ít thôi, nên nằm sân là chính, thì thành tích đã khá hơn rất nhiều. Tất nhiên nói thì dễ, chứ không phải đội nào cũng nằm sân một cách tự nhiên và chuyên nghiêp như người Ý.
Giải 82 có thể thức thi đấu oái oăm, là sau vòng bảng lại là một vòng bảng khác. Mỗi bảng không phải bốn đội mà là ba. Lý do là giải có 24 đội, và chưa có sáng kiến là lấy thêm mấy đội thứ 3 có kết quả tốt. Liên xô của chúng ta ở cùng bảng Bỉ và Balan. Bỉ lúc đó là á quân châu Âu (thành tích cao nhất của đội này từ trước đến nay), và thắng đương kim vô đich Argentina của Maradona ở vòng bảng.
Phần 2
….đi xe Honda, sang Tây ban nha, để xem bóng đá…
là lời bài hát chế giai đoạn đó. Để thấy không khí hoành tráng thế nào. Bài này từ khoá không phải Tây Ban nha, cũng không phải xem bóng đá, mà là “xe Honda”.
Honda là xe máy. Nếu bây giờ, bạn sẽ tưởng tương đó là một phươt thủ oai phong, cưỡi quả xe phân khối lớn đi qua muôn trùng rừng núi, để đến nước Tayban nha xa xôi. Hình tuơng này rất chi lãng mạng, nhưng mình ngờ rằng lời hát chủ tâm đơn giản hơn thế nhiều. Bời thời gian đó, phương tiện giao thông cá nhân không có gì hơn xe Honda (Cub) cả. Khái niệm ai đó có một chiếc ô tô, là không tồn tại. Trong tâm trí chúng tôi, chỉ có các nguyên thủ, hay thấp hơn một chút là đi ô tô thôi, và đó phải là ô tô công. Bởi vậy, người bình thường, nếu có phải tự đi đâu, thì oai nhất là Honda rồi.
Chuyện đá bóng giờ kể tiếp. Liên xô của chúng ta vào vòng bảng hai với Balan và Bỉ. Đội Bỉ lúc đó cũng oai, chả kém gì Bỉ hiện tại. Họ là á quân châu âu năm 1980, và các câu lạc bộ Bỉ như Anderletch hay Standard Liege cũng là hạng có sừng có mỏ, không kém cạnh gì Man City hay Tottenham hiện nay. Nhưng trận đầu thua ngay Balan 3-0, Boniek ghi cả 3 bàn. Trận sau với Liên xô, thua tiếp 1-0 nữa, cho thấy sự kém cỏi của chủ nghĩa tư bản.
Trận đấu cuối cùng của bảng đó, như vậy là giữa anh cả Liên xô và em út Balan. “Trong phe mình cả”, các cụ bình luận. Mà em phải nhường anh là chuyện dĩ nhiên, trong nhà mình với nhau. Các cụ cứ yên trí vậy, và ghi sẵn vào lịch đợi xem Liên xô đá bán kết.
Nhưng sự việc trên sân nó lại khác. Chả hiểu kiểu gì, ông em lại chẳng nể gì ông anh. Chảng những thế, đây là một trong những trận căng thẳng và nhiều thẻ vàng nhất World Cup (5 thẻ). Tỷ số thẻ là Liên xô dẫn 3-2, còn tỷ sổ thật là 0 đều. Liên xô về nước với số điểm cao nhất trong những đội không lọt vào bán kết, thành tích khá nhất của họ cho đến tận bây giờ tại các World Cup (tính cả Nga và Ucraina). Balan đi tiếp nhưng đáng tiếc Boniek cũng xơi một thẻ vàng không đươc đá bán kết. Đó cũng là lần cuối cùng Balan vào bán kết một giải lớn cho đến nay.
Ở một bảng khác, đương kim vô địch Agentina thua cả hai trận, trước Brazil và Ý. Các trọng tài thời đó bắt rất lỏng, Mâradona bị các hậu vệ của Ý và Brazil, đặc biệt là Gentile của Ý, cho nằm sân liên tục. Nếu là bây giờ, thì Gentile chắc bị đuổi mỗi trận 2 lần. Nhưng năm 82, như một trò đùa, người bị đuổi lại là Maradona. Anh này bị chém nhiều quá, đội lại đang thua, điên lên đá một cầu thủ Brazil một phát, thế là xơi thẻ đỏ trực tiếp.
Trận cuối cùng giũa Brazil và Ý là trận đâu hay nhất của toàn giải. Trước đó, Brazil thắng Argentina đậm hơn, nên họ chỉ cần hoà là đi tiếp. Nhưng đội này có một điểm yếu, cũng như Barcelona thời hoàng kim đầu những năm 2010, là không biết đá hoà như thế nào. Có bóng là cả đôi ton ton chạy lên rê với sút. Nhưng xui cho họ, đó là một ngày rất đặc biệt của người Ý, vì Rossi cứ chạm chân vào bóng là ghi bàn. Cả 4 trận trước của Ý, anh chả ghi bàn nào. Thế rồi anh ghi cả 3 bàn trong trận với Brazil. Cứ cò cưa một lúc, thỉnh thoảng Rossi ở đâu chui lên đá vào một quả, rồi người Brazil gỡ lại một quả, 1-0, 1-1, 2-1, 2-2. Nhưng đến lần thứ ba thì họ cũng oải, và thủ môn Dino Zoff của Ý cũng có pha cứu thua xuất thần. Các cầu thủ còn lại của Ý phối hợp cũng ăn ý, cho đối phương nằm sân hay tự nằm sân đều đúng lúc, nhịp nhàng. Tóm lại là Brazil về nước mà cho đến nay vẫn chưa hiểu là tại sao.
Các trận sau của Ý suôn sẻ hơn rất nhiều. Balan thiếu Boniek, bị thua 2-0. Rossi lại tiếp tục ghi bàn thay cho toàn đội. Trận chung kết, anh lại ghi bàn đầu tiên mở màn, tức là trong hơn 2 trận đấu rưỡi (với Brazil, Balan, Đức), anh là người duy nhất ghi bàn cho tuyển Ý; 6 bàn trong 6 hiệp. Người Đúc thua một quả, nhưng họ không phải Brazil, và chắc cũng oải vì trận bán kết, thua thêm 2 quả nữa trước khi gỡ được một bàn danh dự khi trận đấu đã hoàn toàn ngã ngũ.
Trận duy nhất gay cấn là trận bán kết giữa Đúc và Pháp. Nó được Planiti ghi nhớ như là trận đấu đẹp nhất đời cầu thủ của mình. Bây giờ ai cũng nghĩ đội Pháp lúc nào cũng mạnh, vì trong vòng 25 năm gần đây, họ thật sự là đội bóng thành tích tốt nhất thê giới, trong đội lúc nào cũng toàn siêu sao. Nhưng năm 1982 không vậy. Lúc đó Đức là vô địch châu Âu, và cũng cách đó không lâu, 1974, họ vô địch World Cup. Đức là cửa trên, Pháp là underdog, đã lâu lắm rồi không vào sâu ở các giải lớn. Trong bảng bốc thăm, thậm chí họ chỉ nằm ở Pot 3 (tức là gồm các đội hạt giống thứ 3, dưới đội đuoc seed và hạt giống thứ hai). Ở Pot 2 có năm nước Đông Âu (Liên xô, Hung, Balan, Tiêp, Nam Tư) và Áo.
Thế nhưng trong trận, Pháp là đội chơi hay và thoáng hơn. Át chủ bài của người Đức, Rummenigge, quả bóng vàng 81, chấn thương phải ngồi ngoài. Sau 90 phút đầu, hai đội hoà 1-1, với Pháp đá đập cột trong phút cuối. Nhưng sự kiện đang nhớ hơn là quả bay người của thủ môn Đức Shumaker vào Bastiston, với những động tác mà Lý Liên Kiệt, ngay cả trong thời phong độ nhất của mình, cũng phải ghen ty. Cú này gửi Bastiston từ vòng cấm địa vào thẳng nhà thương, gãy 3 xuóng sườn và 2 cái răng. So với nó, cú kung fu của De Jong với Alonso trong trận chung kết WC 2010 chi là một cú gãi của học sinh tập sự, và Lý Liên Kiệt chắc cũng đồng ý như vậy. Điều đáng nói ở đây, là sau đó Schumaker, đáng ra phải bị đuổi và cấm thi đấu chừng một năm, đến thẻ vàng cũng không bị.
Hiệp phụ Pháp vươn lên dẫn 2-1. Người Đức bí, phải gửi Rummenigge tập tễnh vào sân. Vào được vài phút, thì Giresse ghi bàn thứ 3 cho Pháp. Anh này cao có 1.63, tức là còn lùn hơn Quang Hải, và sau được lựa chọn là cầu thủ của nước Pháp mấy lần liền. Nên Quang Hải của chúng ta, ít nhẩt là về mặt chiều cao mà nói, vẫn còn nhiều hy vọng.
Người Đức không bao giờ bỏ cuộc, và Pháp thì cũng chưa phải là Ý, không biết đá thế nào cho hết giờ. Trong 10 phút sau đó, Rummenigge và Foster gỡ lại 2 bàn, làm một cuộc ngược giòng gây cấn và khó tin. Công bằng mà nói cả 2 bàn này đều rất đẳng cấp chứ không ăn may tý nào. Hai đội lần đầu tiên thực hiện tiết mục penalty shoot-out tại một giải đấu lớn, và như ta biết, cứ chơi trò này thì các anh Dức mười lần thắng 9, nên kêt quả cũng không có gì đáng ngạc nhiên.
Dù thua, giải này kết thúc có hậu cho người Pháp, mở đầu một chu kỳ thăng hoa kéo dài cho đến nay. Đội tuyển 82 của họ là nòng cốt của đội hai năm sau đó sẽ vô địch châu Âu, vói Platini ghi 9 bàn thắng chỉ trong 5 trận, và từ đó đến nay, thập kỷ nào họ cũng có một đội bóng lớn vô địch hoặc Ẻuro, hoặc World Cup.
Nhà toán hoc thứ hai được giải Fields năm nay là anh J. Maynar, vỡi những công trình về số nguyên tố.
Số nguyên tố có lẽ là một trong những chủ đề lâu đời nhất và được chú ý tới nhất trong toán học. Các nhà hiền triết Hy lập đáng kính đã nguyên cứu về nó, từ trước khi chúa Jesu ra đời. Rất có thể là trước cả khi Mỵ nương cưới Sơn tinh.
Số nguyên tố là những số nguyên dương chỉ chia hết đươc cho chính nó. Ví dụ như 5; 6 không phải là số nguyên tố vì nó chia hết cho 2. Các số nguyên tố nhỏ nhất là 2,3,5,7,11,13,17,19, 23,29, 31, 37….Số 1, thấp cổ bé họng, không được vào hội. Thật ra lý do sâu xa hơn là vì một định lý, xưa như quả đất, là tất cả các số nguyên dương đều có thể viết dưới dạng tích của một số nguyên tố, ví dụ như 6=2 nhân 3. Ai cũng biết là nhân với 1 thì chả thêm vị gì, nên chàng đã bị loại.
Từ thời Napoleon, người ta đã biết là có vô hạn số nguyên tố. Tức cái dãy 2,3,5…ở trên nó sẽ kéo dài vô hạn. Một trong những câu hỏi nổi tiếng và trung tâm nhất của toán học, là cái sự kéo dài đó nó diễn ra như thế nào. Chẳng hạn bạn thấy ở trên có tới 8 số nguyên tố giưã 1 và 20, nhưng giữa 21 và 40 chỉ còn 4 số. Tức tần suất xuất hiện của số nguyên tố ngày một giảm đi. Cũng như số lần hẹn hò của các cặp vợ chồng trẻ, theo thời gian. Nhưng giảm đi như thế nào ? Trong cả hai trường hợp, bài toán đều chưa có lời giải hoàn chỉnh.
Nói cho chính xác hơn, chúng ta biết khá nhiều về câu hỏi thứ nhất. Định luật phân bố của số nguyên tố, một trong nhưng công trình nổi tiếng nhất của toán học, nói rằng trong N số nguyên dương đầu tiên có chừng f(N)= N/log N số nguyên tố, với N đủ lớn. “Có chừng” ở đây có nghĩa là công thức này có sai số, tạm goi là x(N), nhưng sai số x(N) này nhỏ so với f(N). Chính xác là x(N)/ f(N) tiến đến 0 khi N tiến ra vô cùng. Đinh luật này được hai nhà toán học Hadamard và de la Vallle Paussin chứng minh (độc lâp với nhau) trong cùng một năm (1896), dựa trên một số ý tưởng đột phá của Riemann, tìm ra chừng 30 năm trước đó. Sau chứng minh này, có rất nhiều chứng minh khác được tìm ra. Nổi tiếng nhất có lẽ là chứng minh của Erdos và Selberg (1949). Thật thà mà nói, đây không phải chứng minh hay nhât hay ngắn nhất, nhưng câu chuyện xảy ra giữa hai cụ này là một chương rất đặc biệt trong lịch sử toán học. Ngoài ra công trình này đóng vai trò khá quan trọng trong giải thưởng Fields của Selberg (1950).
Câu hỏi tiếp theo sẽ là cái sai số x(N) là bao nhiêu, hay nói cách khác, x(N)/f(N) tiến đến 0 nhanh thế nào cùng với N. Giả thiết Riemann, giả thiết nổi tiếng nhất trong toán hiện đại, nếu đúng, sẽ cho ta một câu trả lời chính xác. Giả thiết này là một trong những bài toán triệu đô. Theo sự đánh giá của mình, với tốc độ lạm phát hiện tại, thì đến ngày một nhà toán học xuất chúng giải quyết giả thiết Riemann, rất có thể triệu đô sẽ chỉ mua được 5 cân gạo và 3 con gà. An ủi ở đây là cả 3 và 5 đều là số nguyên tố.
Lan man mãi, ta phải quay lại anh Maynard. Gà và gạo được chọn, vì chúng là những thứ rất thân quen với người Việt chúng ta. Nhưng 3 và 5, thì là vì chúng đặt biệt. Hai số này là một cặp nguyên tố “sinh đôi”.
Trẻ con sinh đôi sẽ ra đời sau nhau vài phút. Số nguyên tố “sinh đôi” nếu chúng cách nhau càng ít càng tốt. Trừ cặp 2,3 đáng ghét, khoảng cách giữa hai số nguyên tố phải ít nhất là 2, bởi sau số 2 tất cả các số nguyên tố phải lẻ. Nếu khoảng cách chính xác là 2, thì cặp đó là “sinh đôi”. (Vi dụ 5 và 7 là một cặp sinh đôi khác.) Giả thiết “nguyên tố sinh đôi” (twin prime cọnjecture) nói rằng số cặp nguyên tố là vô hạn.
Giả thiết này cũng vô cùng nổi tiếng, và cũng ôi thôi là khó. Bởi lẽ số nguyên tố, như định lý N/log N ở trên đã nói, ngày càng thưa đi, nghĩa là khoảng cách nói chung phải tăng lên. Thâm chí định lý này nói rằng nếu một số nguyên tố có độ lớn là N, thì khoảng cách đến anh bạn gần nhất của nó, trong phần lớn các trường hợp, sẽ là log N. Giả thiết sinh đôi, bởi vậy, là trái với lẽ thường tình. Nó nói rằng các trường hợp đặc biệt, thậm chí đặc biệt nhất có thể, vẫn xảy ra, và xảy ra vô hạn lần.
Ròng rã nhiều thế kỷ, các nhà toán học căm cụi tìm, hay chứng minh sự tồn tại, của các cặp số nguyên tố mà khoảng cách của chúng nhỏ hơn đáng kể so với trường hợp “thường tình”. Hỡi ơi trời chẳng chiều người, cho đến cách đây 10 năm, kết quả tốt nhất của họ là tìm được những cặp mà log N được thay bằng c log N, trong đó c là một hằng số dương nhỏ bất kỳ với N tiến ra vô cùng.
Chấn động xảy ra năm 2013; nhưng nó lại chẳng phải từ anh Maynard. Chấn động này đến từ Zhang, một nhà toán học gốc Trung quốc, khi anh chứng minh là có vô số cặp số nguyên tố mà khoảng cách giữa chúng nhiều nhất là 70 triêu. 70 triệu nghe có vẻ to, nhưng quan trọng là nó không phụ thuộc vào độ lớn của các số nguyên tố trong cuộc. So với các kết quả trước, nó nhảy vọt khỏi sự mơ ước của các chuyên gia trong cuộc. Thú vị hơn nữa, anh Zhang là tay chơi “nghiêp dư”, theo nghĩa là anh không phải giáo sư của trường đại học nào, và trước đó chả ai biết đến anh cả. Có giai đoạn thất nghiệp, anh còn phải đi bán bánh. Nói nôm na, Lọ lem của toán học đúng là anh.
Đáng tiếc, lúc đó anh Zhang đã gần 60, nên trượt giải Fields. Bù lại anh được khá nhiều giải khác, trong đó có giải McAthur, được coi là giành cho các “thiên tài”. Và anh có job, cố định.
Bây giờ mới đến anh Maynard. Anh bước vào câu chuyện bởi vì khi Zhang đăng công trình của mình và gặt hái vinh quang, Maynard cũng đang trên con đường tiến tới một kết quả tương tự—và lúc đó, mới làm xong luận án tiến sĩ, cũng chả mấy ai biết tới anh hết.
Thường thì trâu chậm uống nước đục, nhưng Maynard không nản chí, vì phương pháp của anh có chỗ độc đáo, khác với phương pháp của Zhang. Nó đã dẫn tới một kết quả mạnh hơn, đó là cho ngoài việc sinh đôi, ta có thể nghiên cứu sinh ba, sinh bốn, sinh năm vvv.
Sự việc bây giờ đã khá dễ hiểu. Nếu tại thời điểm này, bạn chưa ngủ gật hay chuyển sang xem phim ngôn tình, thì dễ dang đoan được kết quả của Maynard là gì: anh ấy chứng mình rằng với số k cho trước (k=2,3,45,..), có một số c(k) chỉ phụ thuộc vào k, để tồn tại vô số bộ k số nguyên tố, trong đó khoảng cách giữa số lớn nhất và số nhỏ nhất bị chặn trên bởi c(k). Trong trường hợp k=2, đó là kết quả của Zhang; ngay trong trường hợp này, c(2) của Maynard cũng giảm đáng kể, từ 70 triệu xuống còn đơn vị trăm. Tuy vậy, việc giảm c(2) xuống 2 (the original twin prime cọnjecture) vấn được coi là quá khó với các công cụ hiện có.
Một kêt quả nổi bật khác của Maynard, cũng về khoảng cách giữa hai số gần nhất, nhưng lại liên quan đến chặn trên. Như đã nói ở trên, khoảng cách này trung bình là log N (nếu hai số ta nói đến có độ lớn N). Tìm ra các cặp có khoảng cách nhỏ hơn log N đáng kể đã khó, mà tìm ra các cặp có khoảng cách lớn hơn log N đáng kể cũng khó nốt. Kêt quả của Maynard hịện đang là kỷ lục cho câu hỏi thứ hai. Ta không viết công thức cụ thể ra vì nó khá phức tạp, nhưng các bước kỹ thuật để đi đến kêt quả này cũng rất sáng tạo.
Một điểm thú vị nữa, cả hai kết quả của Maynard được chứng minh cùng một lúc với Terence Tao (và một nhóm đồng nghiệp). Nhà toán học giỏi có nhiều, nhưng điều đáng khâm phục nhất về Terry là anh ấy có thể làm việc cũng một lúc trên 3, 4 lĩnh vực khác nhau, và trên lĩnh vực nào cũng hoặc đối đầu, hoặc cộng tác, với những chuyên gia đầu ngành của lĩnh vực đó, và tạo ra các công trình bậc nhất. Kiểu như bạn vừa chơi bóng đá với Ronaldo trong trận chung kết C1, và vừa đối đầu với Le Bronn James trong play-off của NBA vậy.
May mắn, Tao đã được giải Fields rồi (ngẫu nhiên, đóng góp quan trọng cho giải của Tao cũng là công trình về số nguyên tố, chứng minh sự tồn tại của cấp số cộng có độ dài bất kỳ trong dãy số nguyên tố, làm cùng với Green). Túm lại, những công trình có tính đột phá về số nguyên tố, chẳng những là hay, mà gần như chắc chắn sẽ dẫn tới các giải thưởng to đùng…
Vậy có thơ rằng
Working hard, day and night
Prime cùng với Prize một vần.
Đặt dấu phẩy đúng chỗ là vô cùng quan trọng. Lấy người mình yêu và không bỏ được, tập 2, đáng tiếc, không có nghĩa là
–Lấy người mình yêu và không bỏ được tập 2,
và cũng không có nghĩa
–Lấy người mình yêu, tập 2, và không bỏ được.
Tình thế không éo le và lãng mạn như hai tình huống trên. Đơn giản, nó là tập hai của môt câu chuyện đã đăng cách đây vài năm…
Giải Nobel kinh tế năm 2012 được trao cho hai cho hai nhà kinh tế Mỹ A. Roth and L. Shapley. Ông Shapley (cũng như một số kinh tế gia lỗi lạc khác) là một nhà toán học (Ph.D in Math). Một công trình nối tiếng của ông (cùng với D. Gale) là lời giải cho bài toán rất khó “Stable Marriage” ,tức là lấy vợ hoặc chống và không thể nào bỏ được. Bài toán này đã được nghiên cứu qua nhiều thế hệ bởi vô số nhà toán học xuất sắc, một số có vợ/chồng, một số không, nhựng lời giải của ông Gale và Shapley được coi là có uy tín nhất.
Để nghiên cứu vấn đề “Lấy người mình yêu và… không bỏ được”, trước hết ta quay lại một bài toán dễ hơn là “Lấy người mình yêu”, đã đươc trình bầy trên blog này. Giả sử ta có một tập gồm N chàng trai tuấn tú (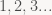

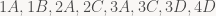
Thuật toán của bác Hall tuy hay, và làm cho ai cũng lấy được (một trong những) người mình yêu. Nhưng đáng tiếc, nó không đảm bảo sự bền vững của các mối quan hệ. Ví dụ, một lời giải cho tình huống ở trên là 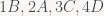
Bác Gale và Shapley của chúng ta đã rất tài tình tìm ra được một thuật toán làm cho tình huống éo le trên không xẩy ra được. Trước hết, họ cho điểm các mối quan hệ, ví dụ
1—>A: 6 diểm (nhanh nhẹn , xinh vừa vừa, nấu ăn ngon nhưng không chịu rửa bát, nghiện phim Hàn Quốc hay khóc thút thít, chụp ảnh selfie hay dơ ngón tay chữ V)
A—->1: 5.5 (Cao to khoẻ mạnh, học hơi dốt nhưng khéo tay, tất nhiên không biết nấu ăn và cũng không thích rửa bát, nghiền chuyện chưởng)
D—–>4 :2 (Lười tắm)
Cuộc hôn nhân được coi là bền vững (stable mariage) nếu ta không tìm được hai cặp, chẳng hạn như 1B và 2A ở trên, với 1 đánh giá A cao hơn B và A đánh giá 1 cao hơn 2. Gale và Shapley đưa ra một thuật toán khá đơn giản để tìm ra stable marriage.
Trong bước thứ nhất, mỗi anh chàng sẽ cầu hôn với cô gái mà anh ta thích nhất. Mỗi cô gái sẽ trả lời một cách lửng lơ “Để tớ xem”, với anh chàng sáng giá nhất trong những cây si, và đá đít thẳng thừng những chàng còn lại. Sau bước này, nàng coi như có “hẹn ước” với cây si cao nhất đó, và chàng cũng coi như có “hẹn ước” với nàng.
Trong những vòng tiếp theo, mỗi chàng trai chưa có hẹn ước sẽ ngỏ lời với cô gái mà anh ta thích nhất vẫn còn nằm trong danh sách những cô chưa đá đít anh ấy. Anh chàng sẽ không quan tâm là cô gái đó đã có hẹn ước hay chưa. (Chiến thuật mặt dầy này được ứng dụng trong thực tế rất hiệu quả.) Về phần các cô gái, nếu được môt anh chàng mới ngỏ lời, lẽ dĩ nhiên, nàng sẽ cân nhắc so sánh với cây si hiện có (nếu có), và sẽ giữ lại cây cao điểm hơn.
Thuật toán này đảm bảo tất cả mọi người đều lập gia đình. Một cô gái nếu một khi đã có hẹn ước, thì từ thời điểm đó trở đi, sẽ liên tục có hẹn ước (có thể với những chàng trai khác nhau), và sẽ nhất định lấy được chồng. Một chàng trai nếu chưa tán được cô nào thì sẽ tiếp tục ngỏ lời với tất cả những ai có thể. Gale và Shapley chứng minh rằng nếu sô nam và nữ bằng nhau, thì cuối cùng tất cả mọi người đều lập gia đình, và hôn nhân này là bền vững. Happy End ?
Nhưng chuyện chưa kết thúc ở đây. Câu hỏi thât sự day dứt của tât cả các cô gái là:
-Trong cái danh sách (dài) của mình, mình sẽ lấy được anh chàng thứ mấy ?
(Danh sách thường bắt đầu bằng George Clooney hoặc Bratt Pit và kết thúc bằng thằng-nhóc-lùn-tì-bàn-bên-cạnh-hồi-đi-học-nó-hay-chọc-thước-kẻ-vào-người-bà.)
Câu trả lời thật sự gây bất ngờ !
Để trả lời câu hỏi sống còn trên, ta cần có một mô hình toán học. Tất cả các mô hình toán học liên quan đến đời sống đều có yếu tố ngẫu nhiên, cũng như bản thân cuộc sống vậy.
Giả sử trong thành phố có N chàng trai và N cô gái, để đơn giản, mỗi người xếp hạng tất cả N nhân vật phía bên kia. Ta giả sử các xếp hạng này là ngẫu nhiên, phải chăng vẻ đẹp trong mắt mỗi con người là khác nhau, chẳng hạn rất nhiều người quan niệm là phụ nữ quyến rũ là phải hơi béo.
Môt đồng nghiệp người Nga, cụ Pittel, chừng 30 năm trước, chứng minh rằng trung bình các chàng trai sẽ lấy được cô gái đứng cỡ 
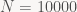
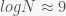
Điều trớ trêu là lời giải này không đối xứng: các cô gái sẽ không lấy được các chàng trai top ten trong list của họ !! Pittel chứng minh rằng, trung bình, họ sẽ lấy các anh xếp hạng cỡ 

Bí mật ở đây là thuật toán của Gale-Shapley không đối xứng cho nam và nữ, bởi các chàng trai luôn là người cầu hôn. Thế mạnh của kẻ chủ động. Phụ nữ đã nghĩ một cách rất ngây thơ là càng được nhiều người cầu hôn càng có giá, và, thật đáng tiếc, đã không đọc bài của Pittel !
Thế nhưng, lưới trời lồng lộng. Sự bất đối xứng này được giải quyết bởi sự bất đối xứng khác. Cũng bởi nam giới có một số lợi thế, nên ở các nước châu Á, nam thường nhiều hơn nữ. Giả sử có thêm môt anh chàng vào cuộc chơi, tức là 
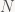
-Các chàng trai sẽ lấy các cô thứ 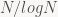
-Các cô gái sẽ lấy các anh top ten (chính xác hơn, top 
Hỡi ơi, người tính không bằng trời tính. Dù ai có dầy công chuẩn bị một (số) cuộc cầu hôn công phu, nhưng chỉ cần một anh phá thối thì công sức cũng ra biển mà thôi.
Ngày Valentine đang đến. Và cái sự cầu hôn kia, rất có thể sẽ thành sự thật. Khi bữa tối đã gần xong, ánh nến đã lung linh, hoa hồng đã cầm tay, và chàng trai khốn khổ đã run run cất tiếng, bạn hãy hít môt hơi dài, nhìn vào mắt chàng, sâu thẳm, và thầm thì câu hỏi quan trọng nhất của đời mình:
–Vậy danh sách của anh có bao nhiêu người ?
Lại sắp đến một mùa World Cup. Ôn lại chuyện xưa, một trong nhưng nhân vật nổi tiếng nhát của WC 2010 là anh Paul bạch tuộc. Bạch tuộc đây không phải tên hiệu của Paul, như Hải rồng xanh hay Hoàng sư tử. Paul la một bạch tuộc chính cống, tức là nó có 8 vòi, và bơi trong một bể nước.
Paul nổi tiếng vì nó đã đoán trúng kết quả cả 7 trận đấu của tuyển Đức. (Paul mang quốc tịch Đức, hay chính xác hơn, nó cư trú trong bể cá của một quán ăn tại Đức.) Phải nói rằng đoán trúng kết quả 3,4 trận đấu liên tiếp là điều rất ít nhà bình luận thể thao nào làm được . Duy nhất có xác xuất gần 100 phần trăm ngang với Paul, không ai khác ngoài Pele vĩ đại, người thường xuyên đoán sai hầu như tất cả các trận đấu.
Sau trận đấu thứ 5, Paul đã nổi tiếng đến mức mà dự báo của nó được truyền hình trực tiếp trên TV. Như bạn đã đoán ra, Paul không nói tiếng Đức cũng như tiếng Anh. Nó dự đoán bằng cách chọn một trong hai hộp thức ăn, mỗi hộp mang cờ một đội. Đội nào được Paul chọn là thắng. Trước những trận đấu cuối cùng, hộp thức ăn được trịnh trọng đặt vào bể bởi siêu mẫu Heidi Klump, trong một bộ bikini rất nền nã.
Khi WC kết thúc, tiếng tăm của Paul đã ở vựợt qua biên giới của nước Đức. Nghe nói một công ty truyền thông Nga muốn tuyển chàng về làm việc để đự đoán kết quả bầu cử tổng thống Nga năm 2012. Nhưng Paul đã từ chối hợp đồng tiền tỷ này để sống bình yên ở quê nhà. Cũng có thể nó coi việc dự đoán này là một nhiệm vụ dưới tầm, bởi cả hai hộp thức ăn đều mang hình Putin, một nhìn thẳng và một nhìn nghiêng.
Tuy vậy, ta hãy tạm để việc ca ngợi những phẩm chất đạo đức đáng quí của Paul sang một bài khác, câu hỏi ở đây là: Paul có thực là một bạch tuộc thiên tài ?
Nếu nhìn nhận sự việc một cách thuần tuý toán học, khả năng Paul, hay bất kỳ một chú khỉ đuôi dài, hay chó cún, hay mèo khoang, chọn đúng đội thắng của một trận đấu là 1/2. Đơn giản là chúng không xem đá bóng. Xác suất đúng 7 lần liền là 1/2*1/2…*1/2 =1/128, tức là dưới 1 phần trăm một chút. Bởi vậy không có gì lấy làm lạ nếu bất kỳ bình luận viên danh tiếng nào cũng dự đoán sai một vài trận.
Nhưng ta quên rằng, Paul không chỉ có một mình. Cùng lúc với chàng, có rất nhiều con vật khác, từ chó, mèo, tới gà lợn, ngựa vằn, cùng tham gia cuộc chơi. Sáng tạo hơn cả, có một bà mẹ trẻ dùng ông con một tuổi để xác định đội thắng (bài tập về nhà: tìm vị trí hai hộp thức ăn). Nếu trên toàn nước Đức có 10000 động vật tham gia cuộc chơi, tính cả anh nhóc nói trên, thì trung bình sẽ có 10000*1/128~ 70 đơn vị đạt được kết quả của Paul thần thánh. Dĩ nhiên không phải anh chó cu mèo nào cũng được lên TV, nhưng quả thật sau Paul, rất nhiều các dạng chim sẻ từ Brazil, hay rái cá từ Ai cập, cũng được báo chí nhắc tới với nhũng khả năng không kém phần bí hiểm.
Bài học trên được rút ra từ một nguyên lý rất quan trọng, đó là luật số lớn. Nếu một thí nghiệm thành công với xác suất là p, và ta lập lại thí nghiệm này N lần, thì số lần thành công sẽ xấp xỉ Np, nếu Np không quá bé. Trong trường hợp trên N=10000 và p=1/128.
Những điều thật may mắn (như trúng xổ số) xảy ra với bạn với xác suất rất nhỏ, nhưng nó sẽ xảy ra với nhiều người khác, bởi N, số người mua xổ số là rất lớn. Nếu xắc suất trúng giải lớn là 1 phần triệu, và có 10 triệu người mua vé, thì gần như chắc chắn sẽ có 7,8 nguòi trúng giải.
Với nguyên tắc này, bạn có thể giải thích nhũng tin giật gân ở các báo, như người bị sét đánh hai lần, hay viêc một bà mẹ sinh đôi ba lần trong đời. Những tình huống này đều có xác suất rất nhỏ, nhưng giống như ở trên, N ở đây là số người trên trái đất, một con số rất lớn.
Một nhà chứng khoán dự đoán sự lên xuống của thị trường chứng khoáng chính xác mười năm liền sẽ nổi tiếng là một kinh tế gia đại tài. Báo chí sẽ viết rất nhiều vô kể về nhưng ngày tháng thăng trầm tuổi trẻ của anh ấy, cách mẹ anh ấy cho anh ăn và nghich các chữ số trước khi đi ngủ, cách anh tính tiền cho bố khi đi Mc Donald lần đầu trong đời (bố nhớ rõ hôm đó cả nhà ăn tới 5 loại bánh khác nhau và anh tính đúng đến từng xu; trên thực tế anh tính sai bét, ngoài ra còn đánh đổ coca-cola và bôi ketchup ra váy hoa của mẹ), và những điều tương tự….
Nhưng nếu bạn tập trung tất cả lũ chó cún trong nội thành Hà nội, và cho chúng chơi một trò tương tự, ít nhất sẽ có vài chục chú đạt được kết quả không kém đại gia kia. Nhưng vì chúng là cún, và không nói được những câu rất dài và khó hiểu với nhiều thuật ngữ gốc latinh, nên chúng không được mởi đi diễn thuyết. Và đành nằm dài ở nhà và ngoe nguẩy đuôi.
Hiện tượng đạo văn ngày càng được nhắc đến nhiều hơn trên báo chí, và nhận được sự quan tâm của xã hội. Trong bài này, chúng tôi muốn bàn tới khía cạnh học thuật của hiện tượng này.
Các hành động đạo văn thường được nhắc tới như sau.
Phát hiện: Trong bài báo của A và B có những đoạn giống hệt nhau. (Bằng chứng rõ ràng: bản sao của hai bài báo.) Vì bài của A viết trước của B, và xác suất hai người khác nhau viết một câu dài (hay một đoạn văn vài ba câu) giống hệt nhau là hầu như bằng không, chắc chắn B đã đạo văn của A.
Kết luận: Đạo văn là không thể chấp nhận được trong nghiên cứu khoa học. B cần phải được xử lý.
.
Hai bước này gần như rất logic và thống nhất với nhau. Nhưng thật ra giữa chúng có một bước ẩn. Đó là ta đã đồng nghĩa việc bài báo có những câu giống nhau với việc sao chép kết quả nghiên cứu. Việc không thể chấp nhận được trong khoa học là việc sao chép kết quả và phương pháp nghiên cứu mà không có trích dẫn.
Để có thể hiểu rõ mối liên quan giữa việc đạo văn một cách hình thức (hai bài báo có những đoạn giống hệt nhau) và sự kiện tác giả B sao chép kết quả và phương pháp nghiên cứu của A, có lẽ chúng ta cần đi sâu thêm một chút.
Trước khi nói về đạo văn, trước hết ta cần chỉ rõ: văn là gì ? Trong khuôn khổ bài viết này, văn là môt bài báo khoa học. (Chúng tôi xin nói thêm đạo văn trong khoa học và văn học có những chỗ khác nhau, nhưng ta sẽ không bàn ở đây.)
Một bài báo khoa học thường có cấu trúc như sau:
(1) Mở bài: Giới thiệu vấn đề, lịch sử của vấn đề, các kết quả đã có, các phương pháp đã được dùng vv.
(2) Thân bài: Giới thiệu kết quả mới, so sánh với các kết quả cũ.
(3) Thân bài: Thảo luận về phương pháp dẫn đến kết quả mới, độ tin cậy của phương pháp. Một số ngành, như toán, đòi hỏi chứng minh chặt chẽ.
(4) Cuối bài: thảo luận các vấn đề liên quan, phương hướng nghiên cứu trong tương lai.
Trên thực tế, rất hay có trùng hợp ở phần mở bài. Chẳng hạn, trong một nghiên cứu về chuối, Tiến sĩ A viết
….Trong bài báo”Một số nghiên cứu cơ bản về chuối”, tạp chí Chuối cả nải, số 21, năm 1978, các tác giả X,Y, Z, sử dụng phương pháp ngoại cảm và tích phân trong không gian đa chiều, đã chứng minh một cách tường minh rằng chuối khi chín vỏ sẽ màu vàng, tuy vậy trên một số quả chuối nhất định, vỏ có thể màu vàng chanh.
Vài năm sau, trong một nghiên cứu mới hơn về chuối, tiến sĩ B viết lại y hệt câu này.
Vậy đây có đích xác là một hành động không thể chấp nhận được ?
Bài báo của XYZ là môt bài rất nổi tiếng trong chuối học, và kết quả của họ là kinh điển. Nếu cả ông A và B viết về kết quả kinh điển này giống nhau, không phải chuyện quá ngạc nhiên. Thật ra viết khác nhau mới là lạ.
Phần mở bài, nếu mục đích là liệt kê lịch sử của một vấn đề đã được nghiên cứu lâu, thì các tác giả viết trùng nhau nhiều là điều dễ hiểu. Nếu vấn đề của tác giả A nghiên cứu là hoàn toàn mới và thú vị, do chính ông ấy nghĩ ra, và một thời gian sau, ông B đặt lai vấn đề này với những từ ngữ y hệt như của ông A, và coi nó như mới, khi đó là lúc vấn đề trở nên nghiêm trọng. Và nó nghiêm trọng ngay cả khi ông B không dùng những câu y hệt như của A.
(2) Nếu kết quả hai bài báo giống hệt nhau thì sao ? Bạn sẽ bảo, ồ thế thì đạo đứt đuôi rồi còn gì.
Nếu kết quả của bài báo A là “chúng tôi thực hiện tiêm Vaxin 456F tại Nigeria, và trong số 124 hà mã được tiêm, 32 con có phản ứng rõ rệt, cụ thể là béo lên rất nhanh”, và ông B viết lại y hệt câu này như một kết quả của ông ấy, trong khi chưa bao giờ đặt chân đến châu Phi
(và rất có thể cũng chưa bao giờ nhìn thấy hà mã) thì chính xác, hành động của ông không thể được chấp nhận.
Nhưng trường hợp sau thì sao ?
Ông A “Chúng tôi chứng minh giả thiết “rùa đi rất chậm” của giáo sư C, đặt ra năm 1902, là hoàn toàn đúng, trên cả hai phương diện lý thuyết và thực nghiệm.”
Ông B “Chúng tôi chứng minh giả thiết “rùa đi rất chậm” của giáo sư C, đặt ra năm 1902, là hoàn toàn đúng, trên cả hai phương diện lý thuyết và thực nghiệm.”
Trong trường hợp này, kết quả chỉ là giả thiết là đúng hay sai thôi.
Nếu A và B cùng chứng minh môt giả thiết, thì kết quả của họ (nếu cùng đúng) giống nhau là điều tất nhiên. Nếu đây là môt giả thiết nổi tiếng, thì chắc chắn họ buộc phải trích dẫn kết quả của nhau, vì tất cả các nhà nghiên cứu trong ngành sẽ biết về các kết quả này. Nếu họ chưa làm, biên tập của tạp chí mà họ gửi bài chắc chắn sẽ nhắc nhở họ.
Nếu giả thiết không có gì thú vị, khả năng A và B chả biết gì về nghiên cứu của nhau là có, vì rất có thể cả hai cùng không tin là có người thứ hai trên đời quan tâm đến vấn đề này. Và gần như chắc chắn
biên tập cũng không biết gì về vấn đề này hết để có thể nhắc nhở họ.
(3) Phương pháp và lý luận: Thật ra đây mới là phần đạo văn dễ xảy ra nhất. Và nó không xảy ra ở dạng mà ta nêu ra ở đầu bài, tức là ông nọ sao chép y bản chính toàn bộ lý luận của ông kia vào. Làm như vậy quả thật quá dốt, và tác giả xứng đáng được xử lý.
Cái nguy hiểm thật sự của đạo văn trong khoa học, thật ra là đạo ý tưởng.
Ý tưởng mới hay phương pháp mới chính là phần quan trọng và tinh tuý nhất trong nghiên cứu. Nhưng nó cũng là thứ khó đóng khung nhất.
Bởi ý tưởng có thể thể hiện qua rất nhiều cách, mà nhìn qua chúng có vẻ khác nhau. Một nhà nghiên cứu, cả đời may mắn có 2,3 ý tưởng hay phương pháp mới mà thôi. Trong âm nhạc, một nhạc sĩ cũng chỉ sáng tác theo 2,3 phong cách. Đôi khi cả đời chỉ một phong cách cũng có rất nhiều. Nicolas Cage là một diễn viên nổi tiếng, nhưng trong phần lớn các phim, anh chỉ thoại theo một kiểu.
Tác giả lấy ý tưởng người khác, xào nấu theo một cách khác, hoặc thay đổi một vài chi tiết, và lấy đó làm ý tưởng chủ đạo của mình, cái này mới thật sự là vấn đề lớn trong khoa học, gây ra vô số tranh cãi. Học trò thầy giáo nhiều khi không nhìn mặt nhau là thường. Trong khi đó, các bài báo của họ không có câu nào trùng nhau hết.
Cách tự vệ của nhiều nhà nghiên cứu là đặt cho ý tưởng (phương pháp) mới của họ môt cái tên dễ nhớ, như “chuối lượng tử” (tên khoa học đầy đủ: xác định độ dày của vỏ chuối bằng phương pháp lượng tử), gần như một dạng đăng ký bằng phát minh.
Cách này có thể thành công, nếu ý tưởng mới rất đặc biệt, hoặc nhà nghiên cứu nọ là một cây đa cây đề không ai dám trêu vào, hoặc nhiều năng lượng đi vòng quanh quả đất quảng bá cho công trình của mình. Nếu không, rất dễ ý tưởng đó sẽ được nhắc lại, dưới một dạng hơi khác, và với một cái tên khác.
Qua đây ta có thể thấy việc đạo văn trong khoa học phức tạp hơn lộ trình hai bước nêu ở đầu bài một chút, và trong rất nhiều truờng hợp, cần đến ý kiến của các chuyên gia. Nếu tuân thủ theo lộ trình 2 bước trên một cách cứng nhắc, thì có một ngày gần đây các chương trình máy tính sẽ trở thành các quan toà, và điều đó chưa chắc mang lại lợi ích cho khoa học.
(Các tên gọi và trích dẫn trong bài này hoàn toàn là tưởng tượng. Bất kỳ sự trùng hợp nào là ngẫu nhiên. Tác giả cũng xin thành thật xin lỗi hà mã vì đã gọi chúng là béo.)
Mở bài: Từ lâu, chủ đề nên dậy toán như thế nào rất là nóng. Cái gì nên dạy cái gì không nên dạy: đạo hàm, tích phân, số phức vv.
Tôi dự định viết một loạt bài về vấn đề này, chủ yếu là các ví dụ trực quan, chứ không phân tích các phương pháp sư phạm của thầy giáo hay phương pháp tu duy của học sinh. Đây là bài đầu tiên, viết đầu năm con chó 2018.
……Tết đã hết. Và đã đến lúc chúng ta cần đối mặt với hậu quả của nó. Trung thực và nghiêm túc.
Cân và gương, là những vật dụng quen thuộc trong nhà. Nhưng từ lâu, chúng đã không là bạn. Người quen cũng không. Ta nhìn chúng, nghi ngại và đề phòng, bởi chúng luôn sẵn sàng, và thường không mấy tế nhị, nói cho ta một điều ta không muốn nghe nhất: sự thật.
Béo đã là một quốc nạn. Tất nhiên, không phải ở Việt Nam. Người Việt chúng ta, trong đó dĩ nhiên có bạn, luôn mảnh mai và xinh đẹp. Đã, đang, và sẽ mãi mãi như vậy. Ai nói khác đi, chắc chắn không là bạn tốt, cần xếp xó ngay vào một chỗ với cân và gương.
Béo đây là ở Mỹ. Nơi mà nó đã trở thành chủ đề khoa học rất nghiêm túc. Có khá nhiều các tập san chuyên khảo về béo, được xếp hạng ISI, và ranking (tính theo mức độ trích dẫn) cao hơn các tập san đỉnh của toán học chừng vài chục lần. Hiển nhiên, có rất nhiều giáo sư, tiến sĩ chuyên về béo, giảng dạy ở những trường đại học mà chúng ta ước mơ là con mình một ngày sẽ được bước vào.
Một ngày đẹp trời, một vài giáo sư trong số đó xuất bản chung một công trình hầm hố. Với một dự đoán gây shock là đến năm 2048, tất cả (hay ít nhât là hầu hết) người Mỹ (trừ trẻ con dưới một độ tuổi nào đó) sẽ béo. Béo ở đây có một đinh nghĩa khoa học, mà ta sẽ không bàn tới, bởi trước hết vì nó dài loằng ngoằng, và hơn nữa, bạn cũng không muốn biết.
Bài in ra lập tức gây tiếng vang tung trời, với số lượng trích dẫn nhiều hơn lượng trích dẫn cả đời của rất nhiều nhà toán học tầm cỡ mà tôi biết. Bởi 2048 là một con số cụ thể, và đó là tương lai rất gần.
Tại sao các giáo sư ngành béo lại đưa ra được số đẹp và chính xác như thế ? Tất nhiên, bạn đoán đúng rồi, đó là nhờ toán học. Phương pháp như sau. Trước hết các giáo sư tính tỷ lệ người béo tại Mỹ trong vòng mấy chục năm gần đây. (Tính như thế nào sẽ là chủ đề của một bài khác, vì hiển nhiên không ai, kể cả giáo sư, có thể cầm cân đo đi mấy trăm triệu người.) Nhưng tỷ lệ này, bạn cứ tin tôi đi, có thể tính rất chính xác. Sau đó các giáo sư vẽ một đồ thị, trục hoành (nằm ngang) là năm, trục tung (thẳng đứng) biểu diễn tỷ lệ người béo. Chẳng hạn, năm 1980: 20%, năm 1981: 22%, năm 2000: 30% vv. Mỗi cặp số (năm, tỷ lệ) sẽ xác đinh một điểm trên mặt phẳng toạ độ. Số liệu của mấy chục năm gần đây cho ta mấy chục điểm tương ứng. Sau đó ta sẽ tìm môt đường cong mềm mại nhất nối các điểm này lại. Đường cong mềm mại này được vẽ thế nào, chỗ đấy là toán, nhưng ta sẽ không bàn tới ở đây, vì thật ra các giáo sư đáng kính trên cũng chỉ dùng software có sẵn mà thôi. Điểm mấu chốt là nếu đường cong tiếp tục đi tới tương lai, thì tới năm 2048, nó sẽ cắt trục tung ở điểm 100%. Voila !!
Bài đã có thể dừng ở đây, nếu các giáo sư đáng kính nói trên không đưa ra các kết quả khác trong cùng bài báo. Để tăng thêm trọng lượng (và độ dài của công trình), các chuyên gia này thực hiện các tính toán tương tự cho nam và nữ riêng, và cho các chủng tộc khác nhau (người gốc Âu, gốc Á, gốc Phi vv). Chẳng hạn, cho nam giới, với phương pháp tính toán nêu trên, tỷ lệ 100% béo sẽ đạt đến trong năm 2043, còn cho phụ nữ, sẽ muộn hơn một ít, năm 2052. Điều này hoàn toàn có lý, bởi chị em bao giờ cũng chăm lo nhan sắc hơn, còn đàn ông, đã xấu sẵn lại thêm cẩu thả, thì beó sớm cũng là đáng đời. Nói nôm na, đến năm 2048, cả nhà đều béo, nhưng bố đã béo trước từ năm 2043, còn mẹ đến 2052 mới béo.
Có một điều các giáo sư khả kính quên mất, là mẹ cũng là một thành viên trong nhà, cũng như phụ nữ là một phần (chính xác hơn là một nửa) của dân số.
Việc dạy toán hướng tới cho người học có thể ứng dụng công cụ toán học trong cuộc sống. Nhưng việc biết sử dụng các công cụ này, như các giáo sư nói trên đã làm, chỉ là một phần. Người sử dụng cần được xây dựng một giác quan toán học đủ tốt để cảm nhận được ý nghĩa và tính chính xác của các câu trả lời mà máy tính, hay các công thức, đưa ra.
(Phỏng theo J. Ellenberg: How not to be wrong)
Từ nhỏ, người Việt ta đã làm quen với các anh tướng Tàu.
Các chuyện dã sử Trung quốc (Đông Chu Liệt Quốc, Tam quốc, Hán Sở tranh hùng, Thuyết Đường vv…) đều là những tiểu thuyết thuộc loại gối đầu giường trong nhiều thế hệ.
Các chuỵện này nội dung chính là chiến tranh, trung tâm của nó là các tướng lĩnh. Trẻ con từ bé đã biết đến Hàn Tín, Hạng Vũ, Khổng Minh, Chu Du, Quan Công, và vô số anh tướng Tàu oai hùng khác. Ta như có cảm giác Trung hoa là cái nôi sản sinh không ngừng các danh tướng kiệt xuất của nhân loại.
Nhưng, lùi xa một chút, có một cảm giác không hẳn là ổn. Lịch sử Trung Hoa chứa đựng một quá trình chiến đấu không ngừng với các bộ lạc phương Bắc. Và xem ra, họ không mấy thành công. Để tiện so sánh, tính từ thế kỷ 10 khi Việt Nam giành độc lập cho đến thời cận đại, Trung quốc trải qua bốn triều đại phong kiến Tống, Nguyên, Minh, Thanh. Hai trong số đó (Nguyên và Thanh) được lâp ra qua sự xâm lược của người Mông cổ và người Mãn, các bộ tộc phương Bắc có dân số kém Trung quốc mấy chục lần. Dưới triều đại nhà Tống, Trung quốc cũng có đến quá nửa thời gian khốn đốn đối phó với các cuộc xâm lược của Liêu và Nữ Chân, và chịu mất một nửa lãnh thổ cho đến khi bị diệt vong. Trong cùng thời gian đó, người Việt chỉ có chừng 20 năm mất tự chủ sau khi nhà Hồ bị đánh bại.
Vậy trong thời gian rất dài đó, các tướng Tàu kiệt xuất ở đâu ?
Nếu để ý, các nhân vật lỗi lạc được nêu ở trên, và phần lớn các tướng Tàu oai phong mà bạn biết, đều là anh hùng của các cuộc nội chiến. Không lẽ Trung quốc không sản sinh ra một đội ngũ đông đảo các tướng lĩnh ngang tầm trong các cuộc chiến đấu chống ngoại xâm, diễn ra trong một quá trình rất dài ? Hay đơn giản là các viên tướng của những kẻ xâm lược đã xuất sắc hơn họ ?
Lan man thêm một chút, Trung quốc là nước có chữ viết rất sớm. Các sự kiện, hay truyền thuyết, được ghi lại rất chi tiết. Nếu bạn quan sát tỷ mỷ các hoạt đông của một người trung bình hàng ngày, cũng sẽ có rất nhiều điều thú vị . Tin hay không, chẳng phải chính chúng ta đôi khi vẫn được sếp khen là đáng yêu hay sao ? Dù rằng tần xuất của lời khen này thấp hơn rất nhiều lần so với các động vật khác trong nhà, như mèo và chó, nó cũng thường mang lại sự ngạc nhiên không hề nhẹ. Nhưng về phương diện thống kê mà nói, lời khen này không phải là hoàn toàn không có cơ sở. Các ghi chép công phu cùng số lượng không nhỏ các truyền thuyết về một nhân vật nôi tiếng là nguyên liệu dồi dào cho các nhà văn. Tầm vóc của các bác tướng Tàu chắc phải cảm ơn rất nhiều ngòi bút siêu việt của các nhà văn đồng hương.
Trong một ví dụ tiêu biếu, ta thử phân tích sự nghiệp của Khổng Minh, có thể nói là một soái được nhắc tới nhiều nhất như một quân sư đại tài trong lịch sử Trung quốc.
Khôgn nghi ngờ gì, Khổng Minh là môt người thông minh và có kiến thức cao trong rất nhiều lĩnh vực, liêm khiết và tận tâm với nhiệm vụ. Nhưng thiên tài quân sự của ông phần nhiều được tưởng tượng ra bởi La quán Trung, tác giả tiểu thuyết Tam quốc có ảnh hưởng rất sâu rộng trong văn học sử và cả đời sống hàng ngày.
Các mưu mẹo tuyệt vời của Khổng Minh được viết đến cực nhiều trong Tam quốc, và vô số sách “ăn theo” sau đó (Tam quôc ngoại truyện, vvv). Nhưng nếu đọc kỹ, rất khó có thể phân biệt giữa truyền thuyết và sự thật, và khá nhiều chi tiết mang tính thần thánh hoá, cho trẻ con đọc cho vui (chẳng hạn Thạch trận đồ). Để khách quan, ta sẽ dựa vào các nét lớn được lich sử ghi nhận mà thôi.
Công bằng mà nói, viên tướng xuất sắc nhất trong quân Thục, chính là Lưu Bị. Hai chiên dịch thành công lớn, lấy Đông Xuyên và Tây Xuyên, đều do ông trực tiếp chỉ huy, với tham mưu là Pháp Chính, Bàng Thống, chứ không phải Khổng Minh. Khi Lưu Bị lên ngôi, Pháp Chính là ngừoi nắm quyền cao nhất. Nguỵ Diên được làm thái thú Hán Trung, vị trí quan trọng sau Thành đô, cũng nhờ công lao của ông ta trong hai chiến dịch trên.
Sau khi Lưu Bị mất, các chiến dịch do Khổng Minh chỉ huy chống lại nước Nguỵ, mặc dầu được tả hết sức hấp dẫn với nhiều mưu mẹo tuyệt vời làm trẻ con thích mê, đã không thu được lợi ích gì nhiều.
Quân Thục dưới quyền Khổng Minh chưa bao giờ tiến sâu được vào nước Nguỵ, và sau sáu lần xuất quân, đường biên giới hai nước gần như không thay đổi. Trong khi đó, Hàn Toại và Mã Siêu, trước đó không lâu, đã chiếm được Tràng An, thành phố trung tâm về phía tây của nhà Nguỵ, môt cách tương đối dễ dàng. Trong toàn bộ cuộc chiến, trận đánh lớn nhất ở Nhai Đình, quân Thục thua và thiệt hại rất nặng.
Chíến dịch thành công nhất của Khổng Minh là cuộc chinh phục các bộ tộc phương nam (bình Mạnh Hoạch). Các chi tiết được La quán Trung mô tả rất ly kỳ, nhưng đã được đẩy cao lên quá tầm quan trọng của chúng. Đây là lần đầu tiên Khổng Minh trực tiếp cầm một đạo quân lớn, và để chắc ăn, ông mang theo ba viên tướng giỏi nhất lúc đó của nhà Thục là Triệu Vân, Nguy Diên và Mã Đại, mà có lẽ bất kỳ ai trông số họ cũng đủ sức điều khiển toàn bộ chiến dịch thành công. Vài năm trước đó, Tào Chương (con trai Tào Tháo) bình đinh bộ lạc Ô Hoàn ở miền Bắc, một nhiệm vụ không kém khó khăn, mà không dùng bất kỳ đại tướng nào của bố.
Khổng Minh chọn Khương Duy, học trò cưng của mình, làm người kế nghiệp về mặt quân sự. Kế tục sự nghiệp của thầy, Khương Duy tiếp tục tấn công nước Nguỵ. Các cuộc ra quân liên miên này không mang lại ích lợi gi đáng kể , và đã làm nước Thục kiệt quệ về mặt kinh tế, dẫn tới sự sụp đổ chỉ 30 năm sau khi Khổng Minh mất.
Một nhân vật Việt Nam có hoàn cảnh tương tự như Khổng Minh là Đào Duy Từ. Trong thời ông (thê kỷ 17), bối cảnh Việt Nam khá giống thời Tam Quốc. Chúa Trịnh lập vua Lê lên ngôi, nhưng giữ hết quyền hành. Nguyễn Hoàng vào trấn thủ Thuận Quảng, xây dựng căn cứ phía Nam. Ngoài Bắc con cháu nhà Mạc vẫn giữ Cao Bằng. Đến lúc Đào Duy Từ lên nắm quyền (1627), nhà Mạc đã về hàng chúa Trịnh, Trịnh Tráng quyết tâm bình định phương Nam. Thế lực họ Trịnh hơn họ Nguyễn nhiều lần. Về qui mô, số dân Đàng trong và Thục có lẽ cũng xấp xỉ nhau (nươc Thục thời Tam quốc có chừng 1 triệu dân).
Giống Khổng Minh, Đào Duy Từ được chúa Nguyên tin dùng, cất nhắc từ thư sinh lên làm tể tướng. Ông chấp chính, đắp luỹ để phòng thủ. Đàng Trong lực lượng mỏng hơn nhưng nhờ chiến luỹ chắc chắn chặn được biết tiến của chúa Trịnh, quân dân không bị tổn hại nhiều. Ông không Bắc tiến, mà chủ trương Nam tiến khai khẩn bờ cõi, cùng lúc giúp chúa Nguyễn xây dựng được đinh chế chính quyền rất được lòng dân, đặt nền móng cho một thể chế lâu dài.
Đào Duy Từ cầm quyền vỏn vẹn 8 năm, mà đặt được nền móng 100 năm cho cơ nghiêp của các chúa Nguyễn, được nối tiếp thêm bởi các vua nhà Nguyễn sau đó, tồng cộng hơn 300 năm. Những người được ông tiến cử như Nguyễn Hữu Dật, Nguyễn Hữu Tiến chẳng những giữ được thế cân bằng về quân sự với Đàng Ngoài, mà còn góp phần quyết định cho cuộc khai khẩn phương Nam của người Viêt. Con trai của Nguyễn Hữu Dật là Nguyễn Hữu Cảnh là người xác định chủ quyền của người Việt tại Sài gòn-Gia Định. Đến đời Nguyễn Ánh, Đàng Trong và Đàng Ngoài đã có dân số xấp xỉ nhau. Sự trù phú của đất phương Nam và ảnh hưởng của các chúa Nguyễn ở đây là yếu tố quyết định giúp ông thống nhất được Viêt Nam sau một cuộc nội chiến dai dẳng. Về sự nghiệp mà nói, có lẽ
Đào Duy Từ đã thành công hơn người đồng nghiệp phương Bắc.
Nhưng với cuốn tiểu thuyết thiên tài của La quán Trung, hình tượng vị quân sư đất Nam Dương rất lâu nữa mới có thể có có đối thủ.
Trong bài này, ta bàn tới thể loại tiến sĩ cuối cùng (tây ta ).
Từ hai bài trước, bạn có thể dễ dàng định nghĩa tiến sĩ tây ta là các tiến sĩ ta được đào tạo ở ta theo kiểu tây. Ngắn gọn là làm Ph.D tại Việt Nam. Về chuẩn đào tạo Ph. D, bạn có thể đọc ở bài trước.
Điều kiện nghiên cứu ở Viêt Nam hiển nhiên chưa bằng ở các nước tiên tiến. Nhưng trong các tiến sĩ đào tạo ở Viet Nam, có những người học vấn uyên bác và tác phong làm việc rất nghiêm túc. Họ đang là trụ cột ở nhiều trường đại học và trung tâm nghiên cứu trong nước.
Đáng tiếc, lực lượng này như đang hao hụt dần. Chuẩn mực đào tạo tiến sĩ gần đây, theo như báo chỉ phản ánh, dường như cũng không theo chuẩn tây nữa.
— Vậy thì đây là tiến sĩ kiểu gì ?
Câu hỏi khó này, xin nhường câu trả lời cho một nhân vật nổi tiếng, ấy là anh Shrek (nhân vật chính của bộ phim Mỹ cùng tên). Shrek, như ta đã biết, là một thanh niên khoẻ mạnh nhưng hay nhăn nhó, sống ở đầm lầy. Một ngày đẹp trời, anh lên đường cứu công chúa xinh đẹp đang bị giam trong một toà tháp do một con rồng hung dữ canh giữ. Anh nhận nhiệm vụ này, chả phải vì đọc nhiều chuyện kiếm hiệp mà rách việc sinh ra lãng mạng, mà chẳng qua vì một tranh chấp bất động sản, bởi khu đầm lầy của anh đang bị qui hoạch làm chung cư.
Shrek mò đến toà tháp, làm thế nào né được con rồng, lẻn vào phòng công chúa. Công chúa, theo đúng kịch bản, nghĩ là hiệp sĩ cưỡi ngựa trắng của mình đã đến giết quái vật, lên giường nằm chờ sẵn để đợi nụ hôn nồng thắm của chàng đánh thức mình dậy. Nụ hôn đã không đến, vì Shrek đang lo bị con rồng phát hiện, kéo tuột công chúa chạy bán sống bán chết. Quả nhiên rồng ta thức giấc, thổi ra lửa đuổi theo công chúa và chàng hiệp sĩ bất đắc dĩ. Công chúa chẳng những chả được hôn, ngựa trắng nào có thấy, mà rồng vẫn sống nhăn thổi lứa sém cả mông, điên tiết hỏi
— Này vậy anh là hiệp sĩ kiểu gì ? (what kind of knights are you ? )
Shrek nhún vai,
—Đố biết kiểu gì !! (one of a kind !!)
Một khi đã chạm tới một nhân vật tầm cỡ như Shrek, ta cần đi tới tận cùng của vấn đề. Sự thật, sinh viên khi bắt đầu làm Ph.D, dù ở Viêt Nam hay Mỹ, có rất ít khái niệm về chuẩn mực của bằng tiến sĩ nói riêng, và khái niệm về nghiên cứu cao cấp nói chung. Đó là chưa nói tới sự nhầm lẫn giữa hai khái niệm tiến sĩ ta ta và tây tây mà ở Việt Nam thường thấy. Tức là làm tiến sĩ cho nó sang (!?)
Người chịu trách nhiệm dẫn dắt cho sinh viên vào con đường nghiên cứu, và chịu trách nhiệm về chất lượng của luận án tiến sĩ của họ, không phải ai khác, là giáo sư hướng dẫn.
Giáo sư giỏi có thể hướng dẫn cùng một lúc nhiều nghiên cứu sinh, mà tất cả đều có thể đạt được chuẩn quốc tế, vì họ biết và theo sát những vấn đề và phương pháp mới trên thế giới, thấy được sự liên hệ giữa các lĩnh vực khác nhau. Nhưng hiện nay, học vị giáo sư dường như chỉ là tấm bằng khen. Các thống kê nhiều lần đăng trên các báo cho thấy rất rõ có rất nhiều giáo sư không nghiên cứu mà cũng chả giảng dậy.
Và câu hỏi của bạn, môt lần nữa, đã được Shrek trả lời.
Đây là bài tiếp theo bài Tiến sĩ (ta ta) pót mấy hôm trước. Hôm nay ta nghiên cứu hai tập hợp tiếp theo, là tiến sĩ tây tây và tiến sĩ ta tây.
Tiến sĩ tây tây định nghĩa rất dễ. Họ là tiến sĩ tây đào tạo ở tây.
Vậy tiến sĩ tây tây giống và khác tiến sĩ ta ta thế nào ?
Điểm giống duy nhất có lẽ là cả hai bằng cấp (nếu thực chất) đều khó đạt được. Các cụ đỗ tiến sĩ ngày xưa, thường là công lao học hành (dùi mài kinh sử) từ lúc để chỏm, cũng phải vài chục năm. Người tốt nghiệp PhD ngày nay, độ tuổi trung bình cũng gần 30, tức là học hành liên tục cũng hơn 20 năm rồi.
Còn lại có lẽ chỉ do sự trùng hợp trong cách dùng từ mà thôi. Cả cách học và công việc của hai loại tiến sĩ này khác nhau.
Tiến sĩ tây, như ta đã biết, gọi chung là Ph.D (Doctor of Phylosophy). Phylosophy là Triết học. Môn này hiện nay rất ít người học, nhưng ngày xưa bên Tây thì tất cả các ngành khoa học cho hết vào đấy, nên gọi thế thành quen. Doctor là học vị hàn lâm cao nhất. (Các nước Âu Mỹ, mỗi nước lại có một hệ thống riêng, nhưng những nét chung tương đối giống nhau.)
Học Ph.D là học chuyên ngành. Ngừoi làm bằng Ph.D, trước hết phải học tốt các kiến thức cơ bản trong chuyên ngành của họ, làm quen với việc nghiên cứu, đọc hiểu được các kết quả và phương pháp mới. Cuối cùng, để tốt nghiệp, phải có được một công trình mang lại một cái gì mới (dù nhỏ) trong lĩnh vực của họ.
Người Tây rất tỷ mỷ, phương pháp làm việc khoa học, ghi chép kỹ càng (chẳng hạn nhiều chi tiết thú vị trong lịch sử Viêt Nam được tìm thấy trong các ghi chép của các giáo sĩ phương Tây qua truyền đạo, và mới mẻ với chính người VIệt chúng ta). Bởi vậy, làm được cái gì mới, dù nhỏ, cũng không dễ, vì trước hết phải học hết những cái đã có đã. Bằng Ph.D thường làm mất 5-8 năm, tuỳ theo ngành (tính cả thời gian làm thạc sĩ mà một số nơi yêu cầu). Tất nhiên cũng có những người xuất sắc có sẵn công trình từ khi học đại học, làm Ph. D chỉ 1, 2 năm là xong, nhưng những trường hợp này rât ít. Hiện nay, khi đã làm Ph.D, các chuyên ngành ngày càng hẹp. Ngừoi ngành nọ nói chuyện với người ngành kia không hiểu nhau là chuyện rất bình thường.
Ở xu hướng ngược lại, học tiến sĩ (ta ta) ngày xưa tất cả mọi người đều học từ những sách giống nhau, ta gọi chung là sách thánh hiền, do các cụ thánh hiền đã chết từ rất lâu để lại. Đã là sách thánh, thì đừng có mong thay đổi gì mất công. Người thông minh phá cách lắm chỉ thêm thắt được những cách giải nghĩa khác nhau cho một vài đoạn thôi. Còn thì đa số là học thuộc sách và lời giảng của thầy. Không có nghĩa là những lời đó không hay hay không sâu sắc, nhưng đời sau không thêm thắt vào được mấy. Kiến thức bởi vậy tăng trưởng rất chậm theo thời gian.
Bằng tiến sĩ ta ta khó hơn, số người được rất ít. Các cụ tiến sĩ xưa làm ngay quan to, lại danh tiếng, nên việc đỗ tiến sĩ được coi là tột đỉnh của vinh quang, cả tổng cả huyện đi đón các ông tân khoa. Các tiến sĩ sau đó trở thành các ông quan, bận việc nhà nước, có đọc sách thêm thời gian cũng rất hạn hẹp.
Học vị Ph.D cũng dịch ra là tiến sĩ. Nghe oai, nhưng thật ra nó chỉ là chứng chỉ cho một người bắt đầu bước chân vào con đường khoa học chuyên nghiệp mà thôi. Chẳng tổng huyện nào ra ra đón, phần lớn các anh Ph. D còn ế vợ, nuôi chó nuôi mèo, con nào cũng gầy nhom vì chủ chưa có việc. Bằng Ph.D chỉ là một xác nhận là anh có khả năng làm nghiên cứu. Còn có đi được tiếp không, là một câu hỏi lớn. Chỉ 1/10 số Ph.D về toán tốt nghiêp hàng năm ở Mỹ về sau trở thành các nhà nghiên cúu thực thụ, tức có chỗ đứng trong các viện đại học hay viện nghiên cứu lớn. Phần còn lại đi dạy học ở các trường nhỏ hơn, hay làm trong ngành công nghiêp hoặc kinh doanh. Họ vẫn dùng, và vẫn có thể, ở một chừng mực nào đó nghiên cứu, toán. Nhưng các kết quả nổi bật từ nhóm này là không nhiều.
Tiến sĩ ta tây là những người sinh ra và lớn lên ở quê ta, nhưng được tây đào tạo thành tiến sĩ ở tây theo lối tây. Mặc dầu vẫn thích nước mắm, kiến thức và quan niệm cùng chuẩn mực về nghiên cứu khoa học của phần đông những người trong nhóm này hoàn toàn tương đồng với các đồng nghiệp tây phương của họ. Hơn nữa, theo thống kê cá nhân, tiến sĩ ta tây có tỷ lệ lấy được vợ hơn hẳn các đồng nghiệp mũi lõ. Điều này hoàn toàn không chứng minh là mũi tẹt đẹp hơn mũi lõ, có lẽ nó chỉ ra rằng vẫn có một sự lầm lẫn rất đáng yêu về khái niệm tiến sĩ trong chị em phụ nữ quê ta.
** Người viết hoàn toàn không chịu trách nhiệm về vấn dề hôn nhân của các tiến sĩ tương lai.
